# System Architecture
As the main goal of the system is to enable live-streaming of truck telemetry data to a fleet manager, the system architecture has to based around the capability of fast delivery of data to where it needs to be. Two general architectures fit this general requirement: Lambda and Kappa architectures. As one main requirement for the development of Horizon as a prototype for a fictional logistics company is future expandability, a Lambda architecture as basis is best suited, as it enables future batch analysis and training of machine learning models during deployment.
# Lambda Architecture
Architecture Overview:
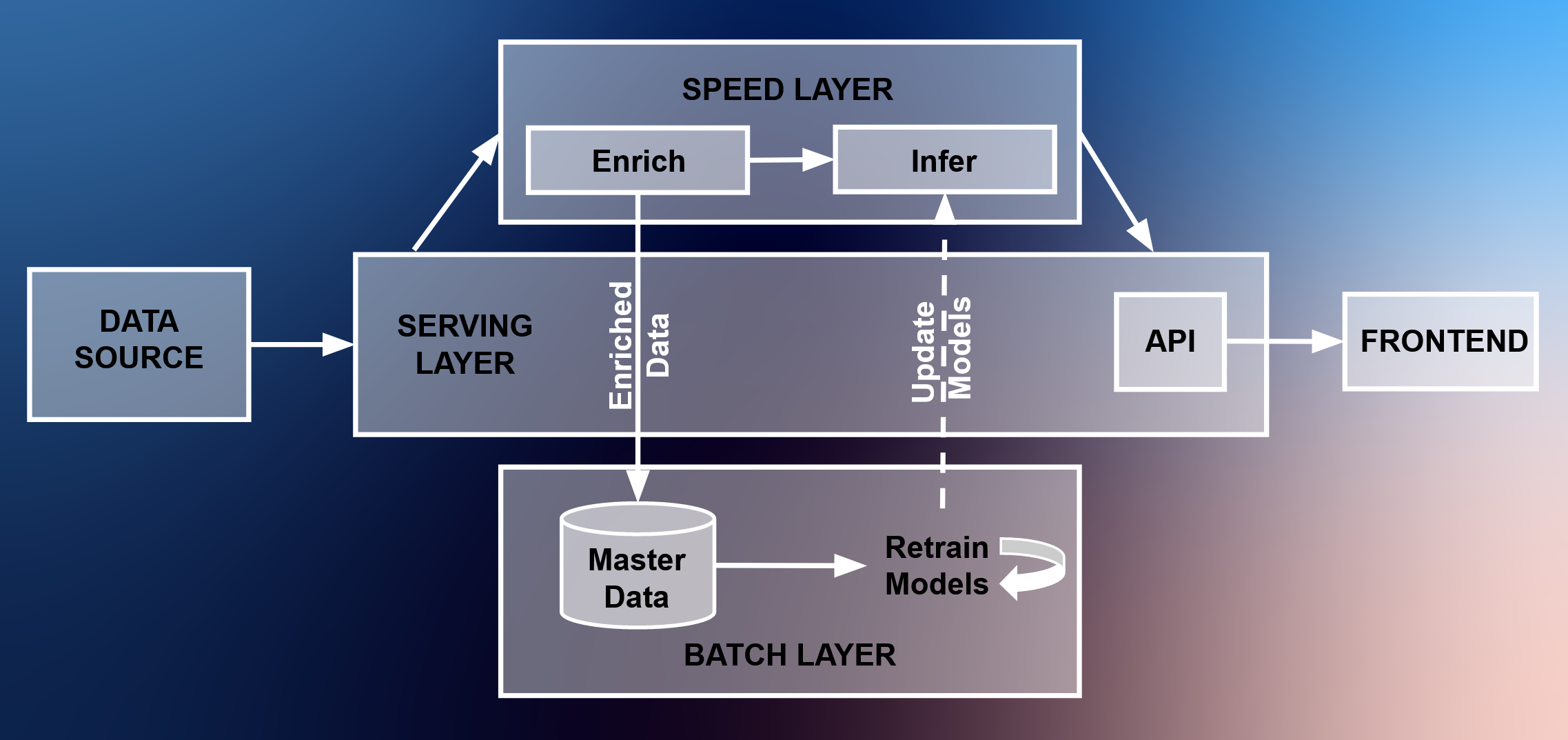
# Individual Components
Horizon consists of the following components:
# Data Source: Simulation
The simulation streams realistic real-time telematic truck data to the message broker inside the serving layer. In a real world scenario the data would of course stem from real trucks. Find more about the simulation and data source here.
# Backend
The backend is responsible for data streaming, data enrichment and aggregation, data persistence and making available data to the frontend. Find more about the backend here.
The backend consists of the speed-layer, batch-layer and serving-layer.
# Serving Layer
The serving layer is made up of a real-time message broker and api-server, providing real-time streaming capabilities and a speed-layer view. The serving layer makes up the foundation of the architecture, connecting almost all components of the system. The only data streams that do not rely on the message broker are the exchange of potentially large machine learning models and aggregations between the batch- and speed-layer, as well as the direct connection to the batch-database inside the speed layer. In a future version of Horizon, the data that shall be saved in the batch-database should be sent to the message broker and saved into the database by another consumer inside the batch-layer to ensure proper separation of concerns. Since this step involves unnecessary computing and administrative effort, the speed layer is able to access the batch database directly in the current prototype version.
# Speed Layer
The speed layer is responsible for (near) real-time data aggregation, enrichment and inference, as well as ensuring ground-truth data is saved into the batch-database. This is a divergence of reference Lambda-architectures, where most of the time, data is directly saved to the batch database from the serving layer, but was necessary to ensure that the batch-database contains important data-points needed for machine learning, which are only available after the data enrichment steps have processed and a truck has arrived at its destination. An example for the necessity of saving the ground-truth data to the database from the speed layer can be seen with weather data, which is added in the speed layer.
# Batch Layer
The batch layer consists of a document-based database and periodically executed batch processing script responsible for historical aggregation and machine learning. In the current state of the system, where historical aggregations are not visualized due to the streaming focus of the system, the batch layer's purpose is to update files required by the speed layer to run. In an extended system, the batch layer would periodically create historical views and statistics on the data in the batch layer and provide these to a separate function in the serving layer.
# Frontend
The frontend consists of a app that fetches the api inside the serving layer in periodic intervals. This ensures that no message consumer logic has to be included in the frontend. In addition, all data is always displayed in a consistent way as delivered by the backend. The main advantage to this approach is the separation of concerns. A new frontend can be developed independently of backend technologies. Dynamic updating of the data inside the frontend can handled by efficient frontend frameworks instead including client logic.
Find more about the frontend here.
Some additional remarks on architecture decisions shall be given by providing an example of the decision making process:
In a real world production system, the information about the current weather is very relevant to fleet managers for historical analysis as well as statistically learning reasons for delays. While these features are not taken into account in the current version of Horizon (mainly because the weather has no influence on the simulation in the current version of fleetSim), they would be in the real world.
The Horizon architecture was modelled to be as useful in a real world scenario as possible. This is also the reason why some potentially very helpful information such as the tiredness of the driver, which is available inside the simulation, are not steamed by the simulation, as they would not be available in the real world.
# Contributors
All group members contributed to the system architecture.